A monthly overview of things you need to know as an architect or aspiring architect.
Facilitating the Spread of Knowledge and Innovation in Professional Software Development
Suhail Patel discusses the platforms and software patterns that made microservices popular, and how virtual machines and containers have influenced how software is built and run at scale today.
In this episode, Thomas Betts talks with Shawna Martell and Dan Fike, about the Navigators program at Carta and how they are finding ways to decentralize decisions and empower individual contributors. The quality of technical decisions is improved, and decisions are reached more quickly because the people involved are close to the relevant context.
Generative AI (GenAI) has become a major component of the artificial intelligence (AI) and machine learning (ML) industry. In the InfoQ “Practical Applications of Generative AI” eMag, we present real-world solutions and hands-on practices from leading GenAI practitioners.
In this podcast Shane Hastie, Lead Editor for Culture & Methods spoke to Charlene Hunter, founder and CEO of Coding Black Females, a community that connects Black women in tech and provides opportunities for learning, mentoring, and career advancement.
Smruti Patel discusses successful platform adoption. She explores topics including failed platform-building efforts, the three pillars of a successful platform, and how to bake in acceleration autonomy, and accountability to a platform.
Learn practical strategies to clarify critical development priorities. Register now.
There are only a few days to save up to 60% off with the special Summer Sale.
Level up your software skills by uncovering the emerging trends you should focus on. Register now.
Your monthly guide to all the topics, technologies and techniques that every professional needs to know about. Subscribe for free.
InfoQ Homepage
Articles
How Platform and Site Reliability Engineering Are Evolving DevOps
Feb 06, 2024
8
min read
The DevOps model has morphed from “nice to have” to “must have” for any company that needs to move quickly from idea to production to product in users’ hands. In fact, DevOps is table stakes. Companies are now looking to grow and more effectively manage DevOps with platform engineering and SRE (site reliability engineering) staff.
No one has these roles perfectly carved out right now – there’s just too much to do and not enough people to do it – but knowing where these three disciplines do and don’t overlap will help organizations evolve and take advantage when they are ready.
You might say that platform engineering is the next big thing in the DevOps world. Platform engineering is not brand new; it’s an emerging model focused on not only simplifying developers’ lives, but also empowering them with a set of carefully curated gold-standard tools.
The goal of site reliability engineering, meanwhile, is to use software and automation to solve problems and manage production systems.
In fact, SREs ideally split their time between operations tasks and development work, such as creating tools, scaling systems, and implementing automation.
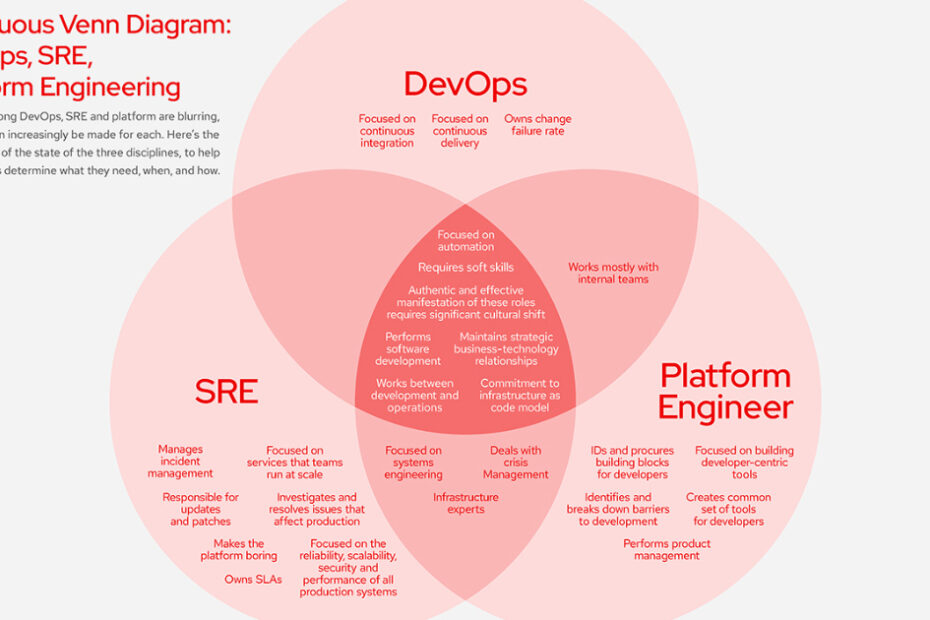
It’s helpful to think of DevOps, platform engineering and site reliability engineering roles in the context of a Venn diagram.
In the Venn diagram pictured below, I have included the granular skills required in, between, and among these three circles.
DevOps teams, platform engineers, and SREs all need to know how to write code, leveraging cloud-native tools such as containers and Kubernetes. But even if they are all experts in the languages, practices, and models currently in use at their organizations, they have to be ready for – and open-minded about – whatever comes next.
The typical DevOps engineer does not have to worry about systems engineering. The typical platform engineer and site reliability engineer do – but not to the same extent.
This is a skill set that might not come immediately to mind, but the ability to effectively manage a crisis is another key capability for both platform engineers and SREs, especially SREs. Folks on the DevOps team might feel differently, but crisis management is not a key area of concern for them.
It may seem obvious to say this (at least, I hope it is), but communication skills matter for every engineer. For SREs and platform engineers, such skills are an absolute necessity because both groups interact with many different groups of people with many different tolerances for risk. For DevOps to work, there needs to be communication between, well, dev and ops. In general, the better the communications, the more effectively ideas move from theory to design and beyond.
DevOps teams don’t really need to worry about product management skills, nor do SREs. Platform engineers, however, are all about the platform and, therefore, must be all about managing the platform.
As you’re reading this, you may be thinking: I don’t have those three roles in the company, or I have people performing these functions, but not broken out in the way described here.
That’s fine, and more common than not. DevOps, platform engineering and site reliability engineering comprise a continuum, not a hierarchy, and the PE and SRE roles evolve from a strong DevOps foundation.
Smaller companies, for example, may not have enough staff to fill all of these roles, so people end up wearing multiple hats. But as companies mature and grow, it’s important to zoom out and identify when it makes sense to dedicate specific resources. Do you have multiple – like, 20 to 30 – development teams? Platform engineers can identify commonalities across all of them to determine which tools make sense and what tasks can be automated. Are you scaling and scaling fast? You likely need a site reliability engineering function to keep up.
Having said that, it’s important to note the key phrase “dedicate specific resources.” All too often, organizations realize the need for a platform or site reliability engineering and just give people new titles or send them to classes without any real-world context or support.
Neither of these actions alone – or even combined – will be enough.
Building a true platform or site reliability engineering practice requires a purposeful and positive culture shift, with buy-in from top to bottom (and from bottom to top).
As part of this culture shift, it should be OK to fail. Actually, failure should not just be OK but welcome. Most organizations are averse to failure, but it’s only through our failures in these spaces that we can learn and grow and figure out how to best position, leverage, and continue to imagine the roles of DevOps, platform engineers, and SRE.
I’ve seen this play out in large companies that went all in on DevOps and then realized that they needed a team focused on breaking down any barriers that presented themselves to developers.
At scale, DevOps – even with the tools provided by the internally focused platform engineering team – didn’t really cut it. These companies then integrated the SRE function, which filled DevOps’ reliability and scalability gaps.
That worked until these companies realized that they were reinventing the wheel – dozens of times. Different engineering teams within the organization were doing things just differently enough – different setups, different processes, different expectations – that they needed separate setups to put out a service. The SREs were seeing all of this after the fact, which led them to circle back to the realization that different teams needed to be using the same development building blocks. (Back to you, platform engineers.)
Frustrating? Yes. The cost of increasing efficiency in the future? Absolutely.
Indeed, it’s really important that there’s no finger-pointing or wallowing in regret. DevOps doesn’t work at scale? Fine, let’s bring in SRE to help us manage our expanding application portfolio and customer base. It’s a good problem to have! Ten different engineering organizations are doing things in ten different ways? OK, let’s get platform engineering on the job.
No matter how things ebb and flow – and they will ebb and flow – assume and communicate positive intentions. After all, these are bits and bytes we’re dealing with – if the bits and bytes don’t work a certain way, we acknowledge it, rearrange them, and move on.
What will make the DevOps, platform engineering, and SRE functions successful – as they exist on their own and in all of the areas in which they overlap – is the ability to learn from failure and to adapt and change quickly. Disagreeing then committing – as opposed to succumbing to analysis paralysis – allows organizations to keep up a rapid development pace while ensuring that systems are reliable and that the right tools, processes, and people are in place.
Speaking of people, it’s vital to give people opportunities to grow and learn, no matter what their role. Just as you can’t make someone, say, a site reliability engineer just by giving them the title, you can’t discount someone as an SRE just because they don’t have the title (or even the specific training). This goes for DevOps and platform engineering roles, as well.
The people who are the best fit in any of these roles are curious, have a deep understanding of technology, and have demonstrated the ability to effectively collaborate with team members. Look for people who want and are willing to learn. Aligning existing and potential skill sets and mindsets with the key characteristics noted in our Venn diagram can help identify – and retain – your next DevOps, platform, and site reliability engineers.
To be honest, I should have made the Venn diagram graphic interactive, for two reasons: One, the way the functions are distributed among the roles will not be the same for every company. For startups or small companies, for example, the three circles may completely overlap each other. Two, even in a large enterprise where there are very discrete business units and technology functions, things change. The economy changes. Technology changes. People change. And, so, too, will the way the functions fall into place.
There are many factors that will figure into the questions companies should ask themselves to determine which roles make sense and when. But it all boils down to taking stock of applications and what teams are working on. This will enable organizations to proactively determine where roles start to overlap and when breaking out discrete PE and SRE functions from DevOps makes sense.
As the world became digitized, the demand for new apps and services rapidly increased. The DevOps model enabled organizations to meet that demand by accelerating the process of moving ideas from development to deployment. Indeed, in the last decade or so, the DevOps model has delivered increased business value and responsiveness through rapid, high-quality service delivery.
The disciplines of platform engineering and site reliability engineering have emerged to meet the challenge of improving the DevOps process. Dedicating staff to each of these roles may be out of reach today, but building awareness of how the roles complement each other and identifying required skill sets from among existing staff will position organizations to take advantage of the next big things in DevOps.
A round-up of last week’s content on InfoQ sent out every Tuesday. Join a community of over 250,000 senior developers.
View an example
A round-up of last week’s content on InfoQ sent out every Tuesday. Join a community of over 250,000 senior developers.
View an example
June 24 – 25, 2024 | BOSTON, MAActionable insights to clarify today’s critical dev priorities.InfoQ Dev Summit Boston, is a two-day conference hosted by InfoQ, focusing on the most critical technical decisions senior software developers face today.
Deep-dive into 20+ technical talks and get transformative learnings from senior software developers navigating Generative AI, security, modern web applications, and more.Register Now
InfoQ.com and all content copyright © 2006-2024 C4Media Inc.
Privacy Notice, Terms And Conditions, Cookie Policy